- i'm a junior at cornell university studying computer science in the college of engineering
- professionally, i'm interested in software engineering and quantitative finance

Currently, I am working on an offshoot of the hedged sports betting project. Our team is developing a centralized market exchange for English Premier League betting; specifically, since most sportsbooks "lie" on their odds and provide an edge that prevents users from getting the total amount of return they deserve, we seek to generate our own odds on soccer matchups by training an ML model to identify which teams are most likely to win and then rebalancing our odds based on those sentiments. This rebalancing also takes into account the current odds for upcoming matchups provided by sportsbooks, as these are important to provide an initial baseline for our "better" odds.
For me, I am working more on the application side, interfacing with Flask on the backend, React on the frontend, and Amazon Web Services for our database storage for the ML model.
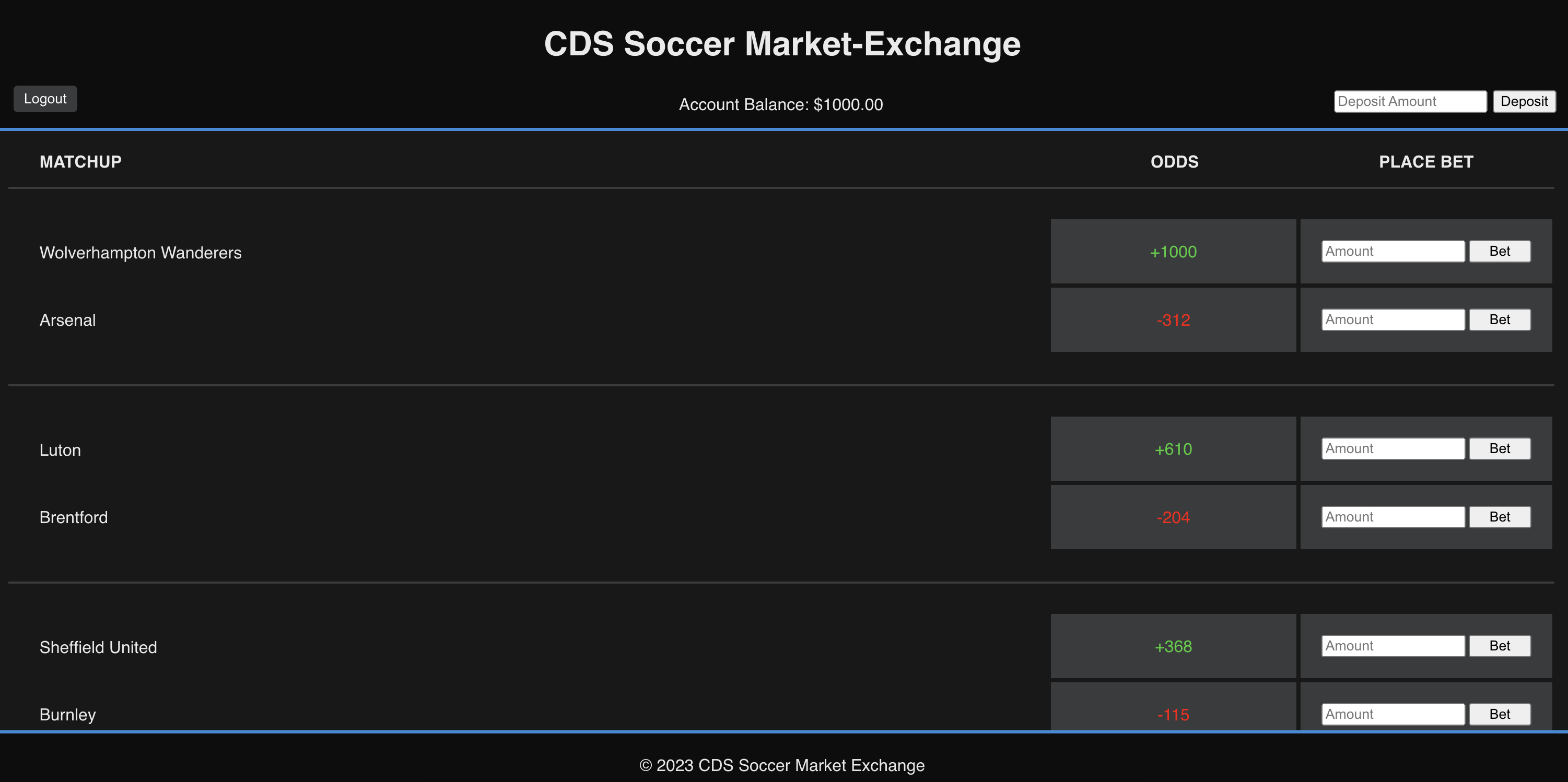
I set up an entire local server on the backend that enables our rebalancing team to trigger a rebalance whenever better odds are generated by our ML model. Further, the odds being displayed on the actual website are being pulled from a third-party API service (displaying the highest positive odd on the underdog and the least negative odd on the favorite). It was important to develop an interactive site that has clearly defined pages and buttons for users to put mock bets on a scenario, which we additionally store on a DynamoDB.
This passion project of mine that I brought to Cornell Data Science involved finding opportunities to exploit arbitrage via sportsbook webscraping, JSON parsing, and arbitrage calculations. Arbitrage is defined as a scenario where two different sportsbooks have alternate odds expectations on a matchup; because of this, placing bets on both sides of the match in both sportsbooks can theoretically make the risk zero.
I utilized BeautifulSoup to scrape data from American and offshore sportsbooks, while overseeing Python request management as some sportsbooks prevent to many pings to their data. Further, I extraced JSON data from a third-party odds aggregating API, and parsed through large responses to get the necessary data we needed (sportsbooks names, odds for both teams, etc. for all matchups in the sport).


Shown above is a sample API output from the third-party service. I had to go through this large dictionary of data and develop a class structure in Python to store "events", and then identify the key tags that were critical for an arbitrage calculation on a matchup. The right image shows a Pandas dataframe from another third-party API for a series of baseball games. As indicated by the arbyHA and arbyAH columns, the higher the first percentage in the tuple the more likely an arbitrage opportunity exists.
We found that over all opportunities found, arbitrage trading led to higher profits in 46.3% of scenarios compared to traditional betting on the favorite. This project was interesting in examining an alternative betting strategy by leveraging computer science fundamentals, but also demonstrated that such a strategy is most likely not feasible for most people unless they have a large amount of data and capital to gamble on.
In this project, I worked on the cloud architecture team in supporting a cloud options trading bot. Specifically, the strategy chosen by the other team was to use a long straddle (buying a put and a call on the same contract) so as to theoretically guarantee risk. In my role, I specifically worked on developing the entire stack on Amazon Web Services by writing out our cloud components (DynamoDB, EventBridge, Lambda) in Python. I also worked to integrate this with the strategy side, which had to webscrape news headlines from Bloomberg, generate sentiment on it with a small Hugging Face model, and write the profit of exercising the strategy to our database.
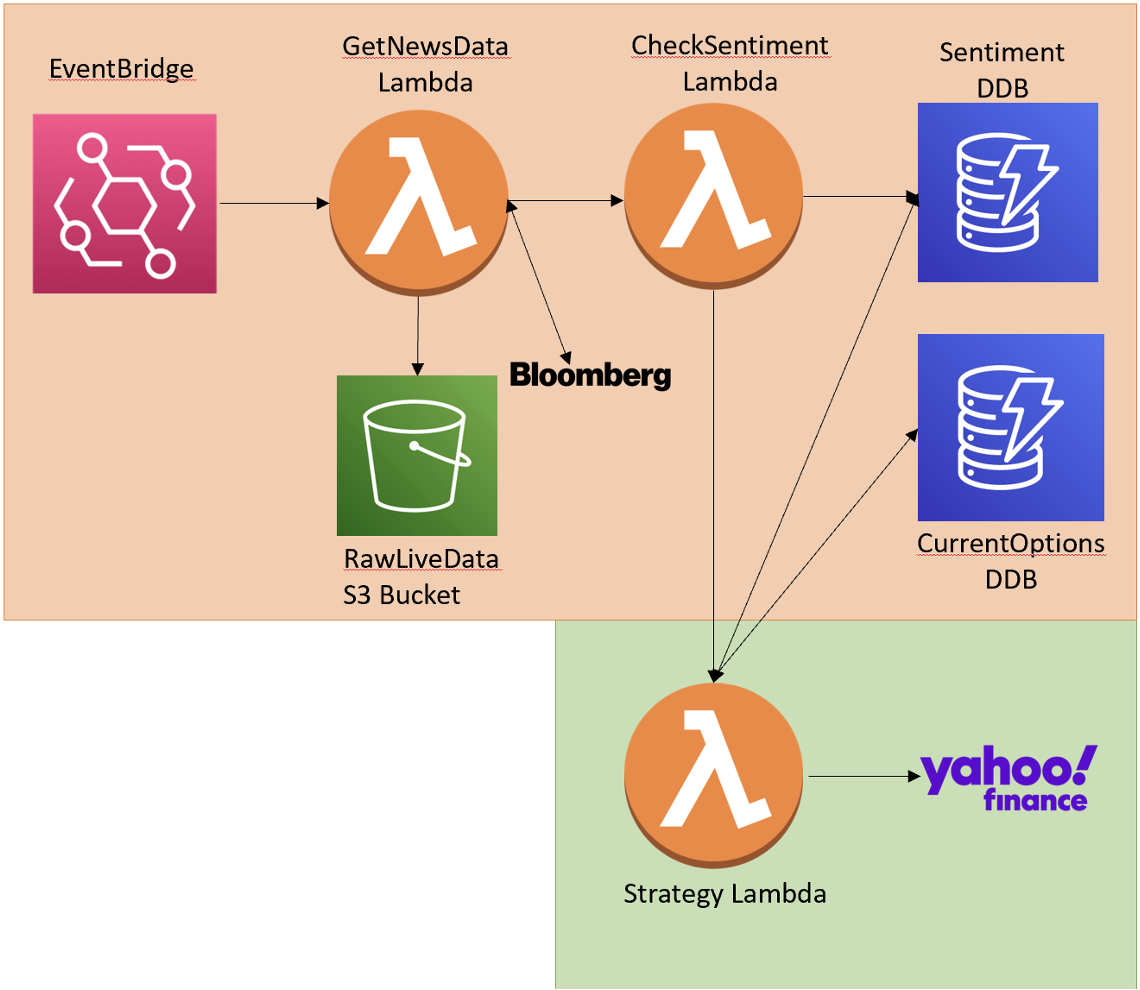
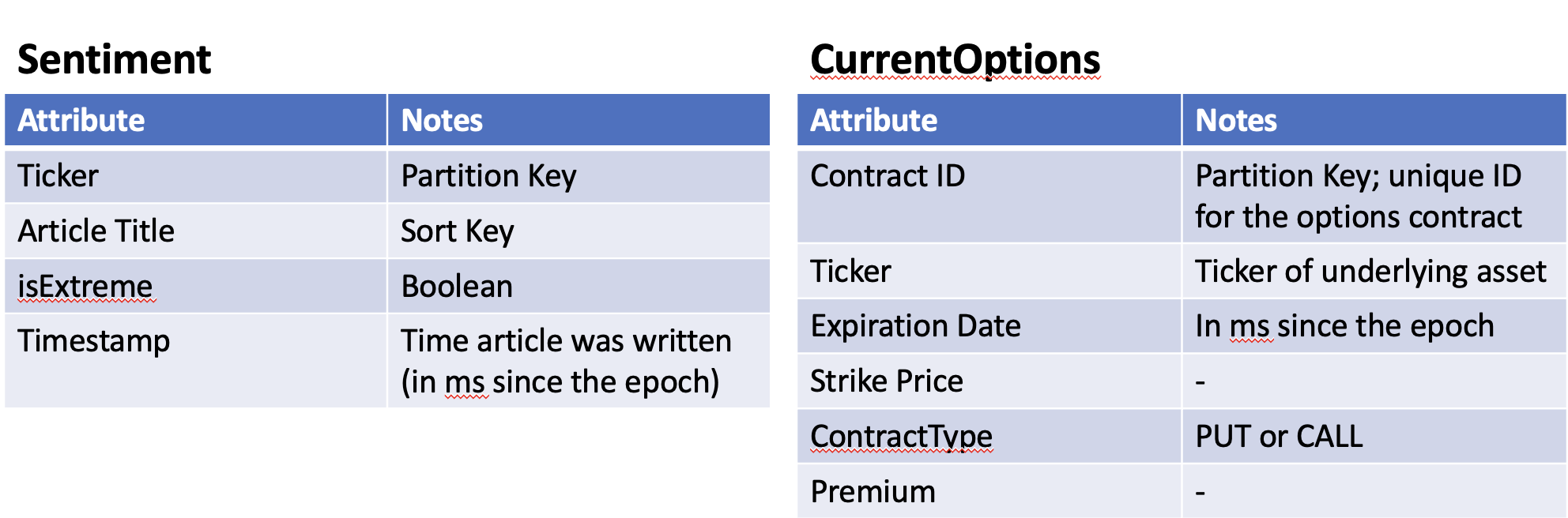
The above image outlines our cloud architecture for the bot's stack. We used AWS Step Functions to link together the subsequent functions of the strategy: webscraping from Bloomberg, feeding those headlines into the LLM model to get a positive or negative output, and then exercising the strategy when favorable and keeping track of that profit in the CurrentOptions database.
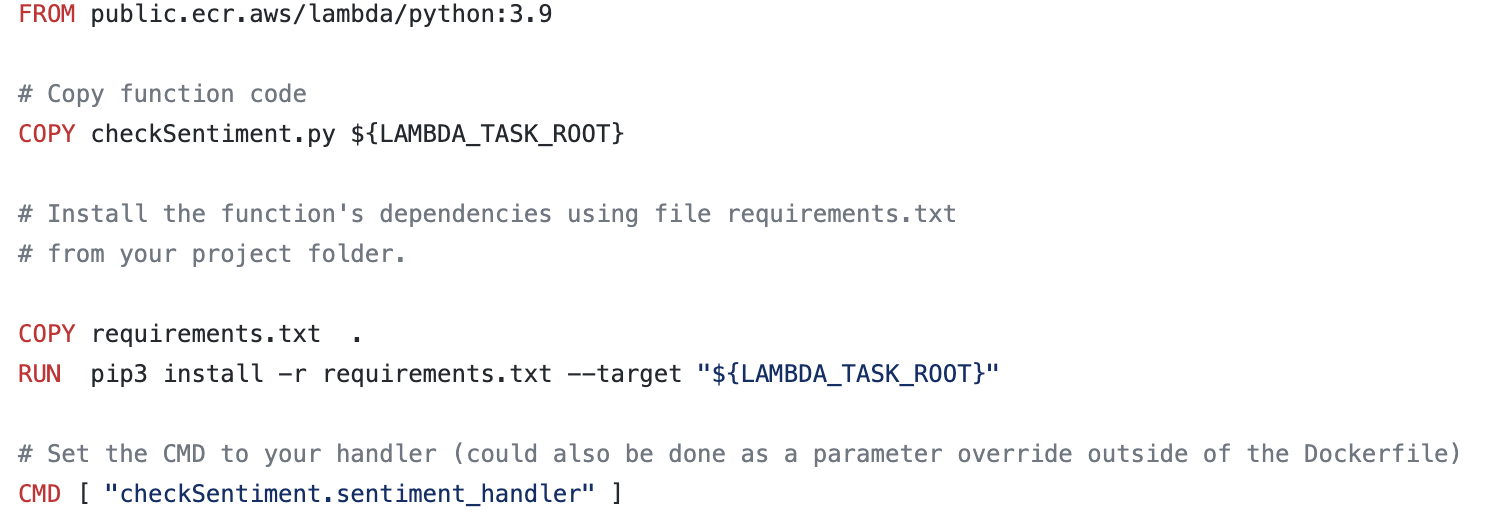
One unexpected difficulty was the fact that we had to leverage Docker to support the dependecies for each of our lambda functions. This was because the LLM model was too large to be supported by AWS. In defining Dockerfiles as shown in the below image, we were able to allocate more space for our lambda functions and create more complicated strategy functions, overall increasing the robustness of our bot.
For our final project as part of CS 3110: Intro to Functional Programming at Cornell University, my group developed a Tamagotchi simulator in OCaml. The simulator enables users to play different minigames, level up their Tamagotchi pet, and buy different trinkets from the in-game currency.

This shows the landing page for our terminal-based simulator, where different text-based inputs can lead to different portions of the project. In fact, you can play this on your own from my GitHub!
In this project during my first semester as a full member of Cornell Data Science, I worked with two
other students in analyzing the optimal
times to employ momentum vs mean-reverting trading strategies. We did this via a common financial
indicator known as the Hurst exponent.
When the exponent is closer to 0, the stronger the mean-reversion process is. The closer to 1, the more
likely the process is to be trending.
By implementing a basic simple moving average strategy and a bollinger band mean reversion
strategy in Python and testing
them on Nasdaq stocks with a market cap over $2 billion by finding the Hurst exponent on the time series
data for each stock, we found the following:
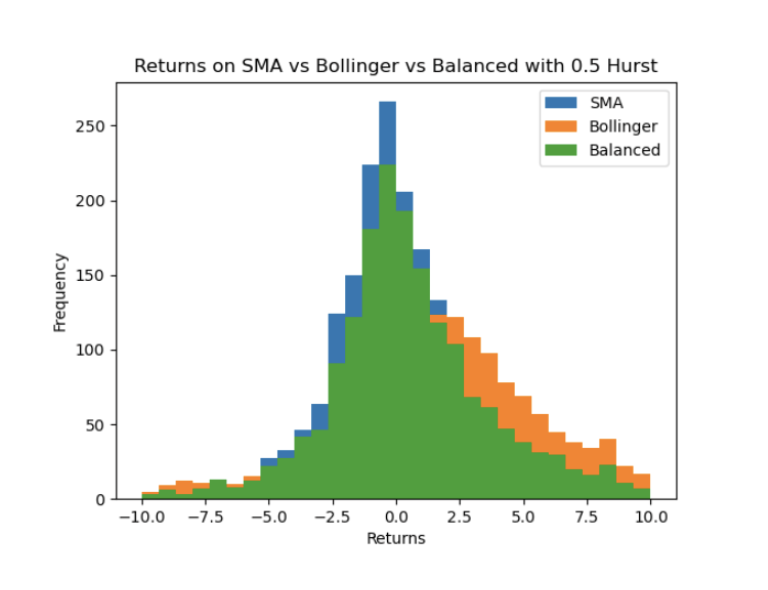
From this, we found that when Hurst exponent analysis was applied to indicate when to use a mean-reverting
or momentum strategy compared to vanilla
mean-reversion/momentum trading, it places risks and returns somewhat between the SMA and Bollinger Band
strategies, effectively hedging risk.
We extended upon this by proposing a reinforcement learning algorithm called Q-learning, which encode the expected value of taking certain actions in certain states, by learning the expected payoff of an action over a training period. The results were promising, as when the algorithm only acted when it expected a payoff it could achieve high returns. However, when forced to act in all scenarios it performed badly. This could imply that the algorithm was better at finding strategies when trained across multiple stocks and time intervals.
This project overall gave me a great introduction into the power of data analysis, finance, and technology all intersecting into one cohesive project. It also made me excited to stay with Cornell Data Science for my college career!